Backpropagation: Differentiation Rules
Derive differentiation rules from scratch with computation graph

Introduction
Backpropagation is a core method to perform optimization in Machine Learning. It is commonly used alongside with gradient descent algorithm, which is explained in my other post.
This is a series of posts on backpropagation. In this post (part 3), we will derive differentiation rules from scratch with computation graph.
The previous posts are prerequisites for this post. Please read them first if you haven't already:
Backpropagation: Differentiation Rules [Part 3, This post]
Some knowledge of derivatives and basic calculus is required to follow these posts.
Differentiation Rules
In the previous posts, we used a computation graph to understand the chain rule and the multivariate chain rule. One nice property of a computation graph is that it enables us to break down a complex function into simpler ones. This breakdown allows us to derive differentiation rules from scratch using a computation graph. Deriving the rules from scratch is fun, and it is also a great way to deepen our understanding of the concepts we've covered so far, such as computation graphs, partial derivatives, and total derivatives.
Constant Rule
Let F(x) = c, where c is a constant that is independent of x, then dF/dx = 0. It is very trivial to proof. We will sometimes use the alternative notation F’(x) for dF/dx.
Let F(x) = c*x, then F’(x)=c, which is derived by:
Let F(x) = x + c, then F’(x)=1, which is derive by:
In a general scenario, if F(x) = k*x + c, then it follows that F’(x) = k. It can be proved in a similar way.
Sum Rule
Let H(F(x), G(x))=F(x)+G(x), we want to find dH/dx (or H’(x)):
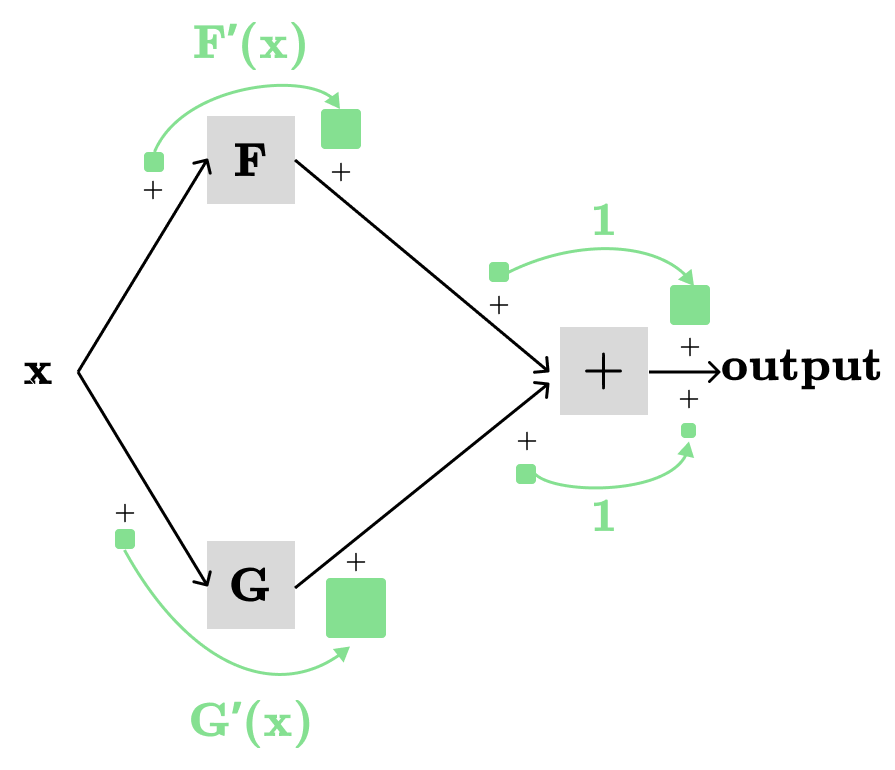
The partial derivatives of the sum, i.e., H(F, G)=F+G, with respect to any of its parameters are always 1, meaning ∂H/∂F and ∂H/∂G are both 1. We already proved this using the rule for F(x)=x+c. Then, the total derivative H’(x) is the sum of products of partial derivatives along the two different paths (see the picture above), which are:
x → F → H → output: F’(x) * 1
x → G → H → output: G’(x) * 1
which nicely gives us:
We can combine the constant rule F(x)=c*x with the sum rule to prove linearity:
As well as the difference rule:
Product Rule
Let H(F(x), G(x))=F(x) * G(x), we want to find dH/dx:
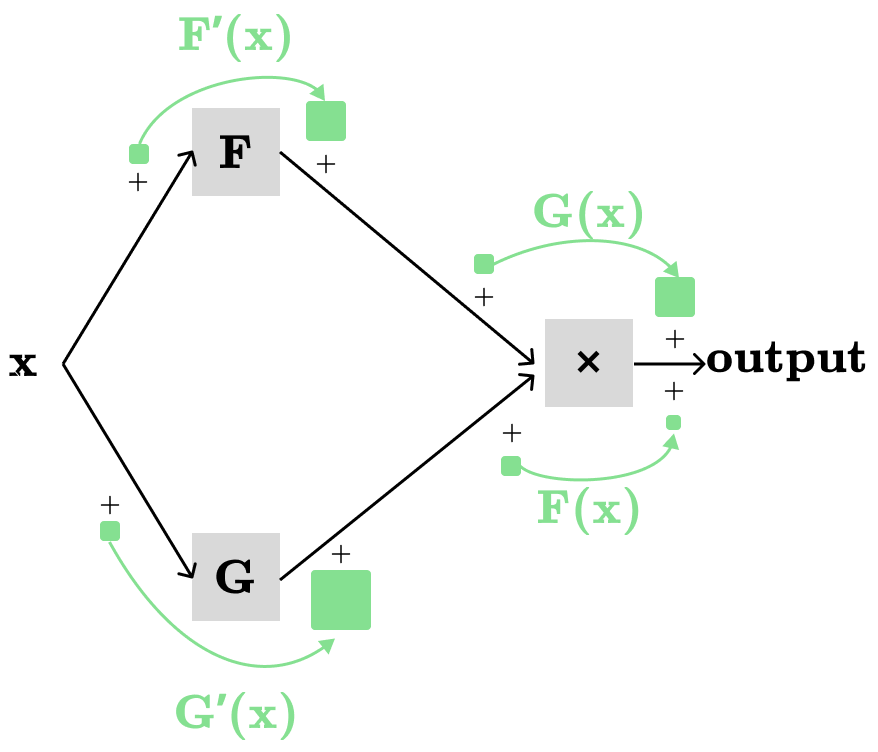
The partial derivatives of H(F(x), G(x))=F(x)*G(x) are:
∂H(x)/∂F(x)=G(x)
∂H(x)/∂G(x)=F(x)
The above partial derivatives are easily derived from F(x)=c*x (see the constant rule section), since we keep the other non-varying parameters constant.
As usual, we have two distinct paths, each contributing to the total derivative:
x→F→H→output: F’(x) * G(x)
x→G→H→output: G’(x) * F(x)
which gives us the product rule:
Power Rule
Let’s begin with the product rule stated above: H(F(x), G(x)) = F(x) * G(x). This gives us H’(x) = F’(x)G(x) + F(x)G’(x). If we use identity functions for F and G, we get F(x) = x, G(x) = x, and H(x) = x^2. From the product rule F’(x)G(x)+F(x)G’(x), we can derive:
Amazing, this demonstrates that we can still break down a complex function into simpler ones, even when those simpler functions share the same variable. By extending the product rule to n parameters we can derive the power rule for H(x)=x^n:
For the sake of completeness, let’s visualize a more general version of the power rule: H(F(x)) = F(x)^n
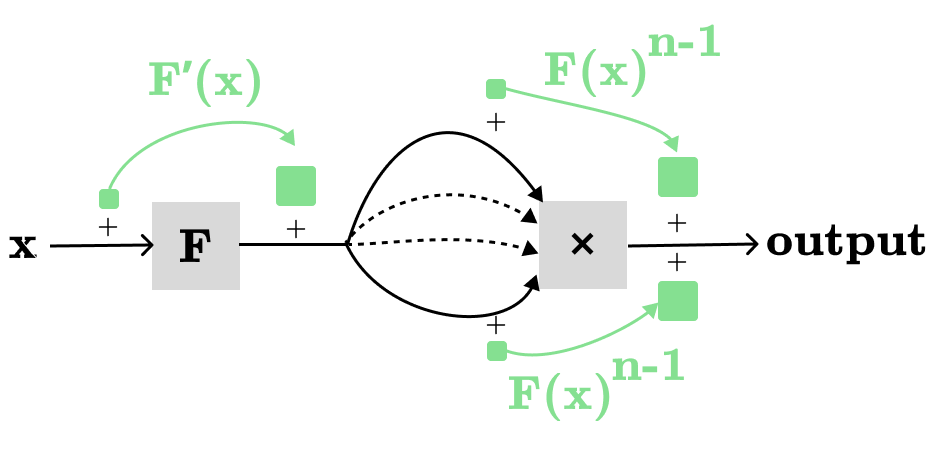
In the computation graph above, we have n different paths, where each path contributing: F’(x)F(x)^(n-1). Hence:
Reciprocal Rule
What is the total derivative of G(x)=1/F(x) with respect to the x?
This time we’re going to use the computation graph differently. Let’s introduce another function H(x)=F(x)*G(x). It is easy to see that H(x)=1, since H(x)=F(x)*G(x)=F(x)*(1/F(x))=1. We already know that dH/dx=0 from the constant rule, and we can also express dH/dx as following:
The following terms are known to us:
dH/dx = 0
∂H/∂F=G(x)=1/F(x) (from F(x)=x*c)
∂H/∂G=F(x) (from F(x)=x*c)
So we have:
which gives us:
Quotient rule
What is the total derivative of H(x)=G(x)/F(x) with respect to the x?
We can compose the quotient rule with the product rule:
The End
This concludes the part 3 of the backpropagation series. Subscribe for the next posts on the backpropagation.